
What is data warehousing ?
Data ware housing is the process of storing company data (such as sales, marketing or any other data and analysis of this data for the benefit of an organisation. The analysis process will generate reports that may be consumed by the management of the organisation to increase productivity. This process will enable to turn an organisation into a data driven enterprise that will make the organisation proactive to future and current trends.
Normally the storage of disparate data would go through a process of formating so that the data can be consumed by analetics engines.
What is a data Warehouse
A data ware house is a place where the data is stored within a data centre for the purpose of analysis. Some times the terms data warehousing and data warehouse are intermitently mixed to refer to the process of data warehousing.
What is Amazon Redshift
Amazon class Redshift as a fast, fully managed, petabyte-scale data warehouse service. In other words its a managed service that an organisation can consume via the cloud to analyse their data. The service is also horizontaly scalable hence Redshift can grow with the requirements of an organization as the organisation itself grows.
Redshift service is optimized for the data warehousing use case, enabling
high query performance querying through columnar data storage, zone mapping, data compression and Massively Parallel Processing (MPP) architecture. Redshift can also be configured via its API. Data can secured via process such as encryption secure SSL connectivity. Data can queried via ODBC and JDBC drivers through reporting tools that utilize SQL. In simple terms Redshift is a clustered data base, with the data spread across the cluster nodes in slices.
Note: Please refer to slices within this article.

The architecture of Redshift consists of a cluster of compute nodes with a leader node. All nodes are linked together in a meshed 10G Ethernet architecture.
Each node has its own local storage. The leader node is utilized to access data via ODBC & JDBC drivers to perfom BI functions and queries on the data.
There are different node types for Redshift based on storage and compute density.
Dense Storage Node Types
ds2.xlarge
ds2.8xlarge
Dense Compute Node Types
dc1.large
dc1.8xlarge
dc2.large
dc2.8xlarge
Please refer to the followin url for more information
https://docs.aws.amazon.com/redshift/latest/mgmt/working-with-clusters.html
vCPU (virtual processor speed)
ECU (EC2 Compute Unit this is to ensure a certain gauranted CPU performance based on amazon compute metrics)
RAM (GiB) (Memory)
Slices Per Node (To be discussed)
Storage Per Node (Amount of storage per node)
Node Range (Amount of nodes that be contained within a Redshift cluster depending on the node type)
Total Capacity (Total capacity of the cluster based on type of node being utilised)
Most of the above are self explanatory, but I've left Slices out so that we can understand the concept of slices
What are Slices ?
Each Compute node in Redshift is partitioned into slices, and each slice receives part of the memory and disk space. Slices process a portion of the workload assigned to the node. The Leader Node distributes data to these slices, allocates parts of a user query or other database operation to the slices. Slices work in parallel to execute and complete these tasks or operations. Slices also have a one to one relationship to the number of CPU cores that are vailable on the node. (1 core = 1 slice )
Compression: Ensure that data is compresed to ensure better performance within a table
AWS Redshift SQL copy command is capable of calculating correct compression while loading data to Redshift.
https://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html
Compression of an existing tabble can be analysed utilising the analyse compression command.
https://docs.aws.amazon.com/redshift/latest/dg/r_ANALYZE_COMPRESSION.html
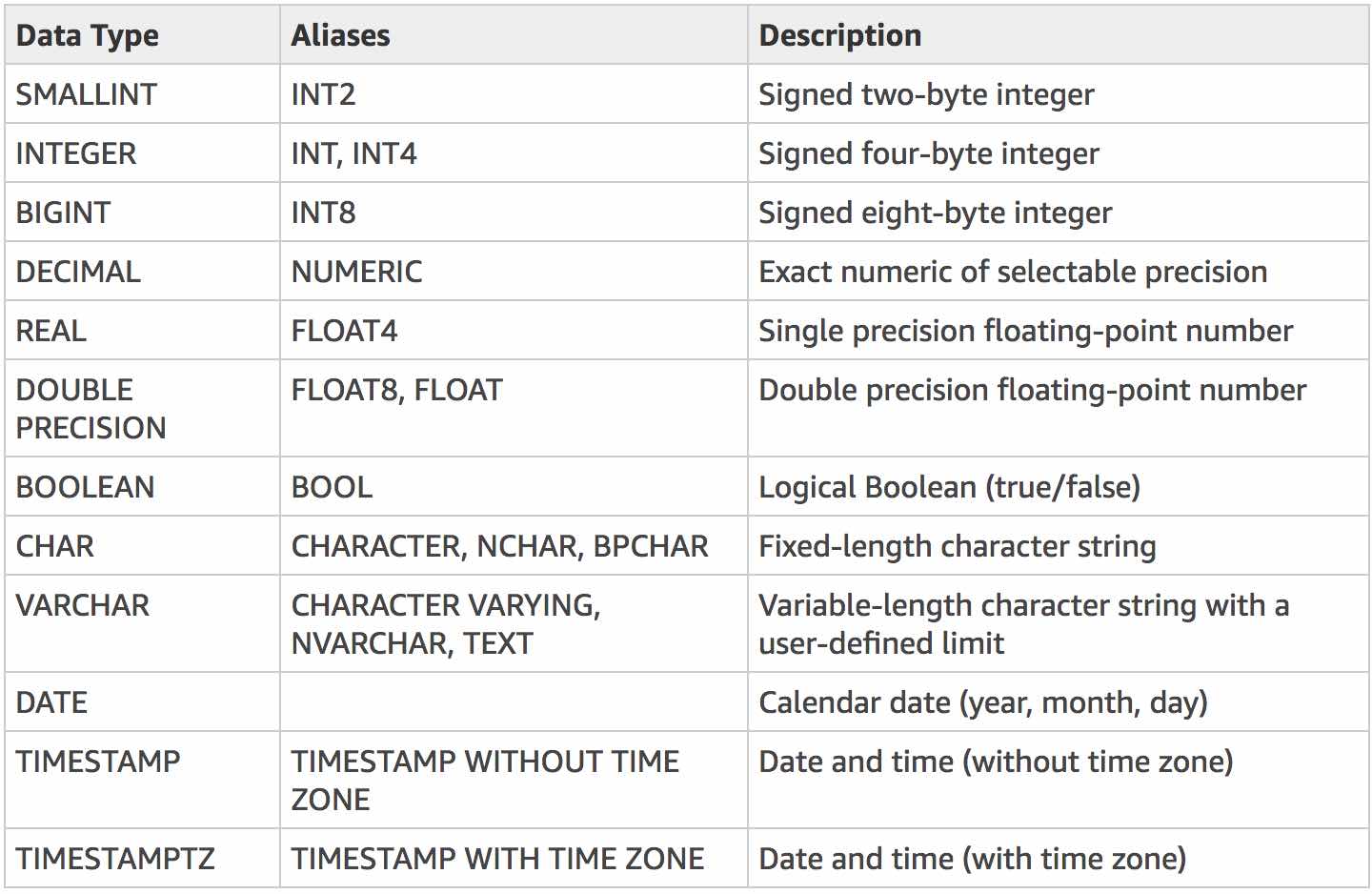
Ensure that the correct Data Type is specified for data. Following are the suported data types.
Ensure to check the following for character lengh and limitations
https://docs.aws.amazon.com/redshift/latest/dg/r_Character_types.html
Schema & Keys
Preferably should be expressed in 3rd Normal Form
Optimize schema for querying
Ensure that data is distibuted optimally across nodes to minimize internode traffic. (This can be achieved by utilising an appropriate distribution key that distributes data optimally to nodes)
Choose an appropriate sort key to sort data for optimal performance
Cache small table utilising the DISTYLE ALL command to cache the tables across all nodes when possible. This reduces inter node traffic.
Utilise the ANALYSE command to ensure data is current post updates.
Redshift does not automatically re claim unused space post bulk deletes, load or incremental update. The VACUUM commad needs to be utilised to ensure reclamaton of unused space. For more refer to the following link for best practices.
Redshift Best practices

Data Loading to Redshift can be achieved via the following AWS services.
AWS Direct connect
VPN connection
S3 Multipart upload
AWS import/export service (Snowball etc)
Direct SQL can be utilized, not recommended for large data sets since data will be sent via leader node serially limiting throughput.
The above services are topics themselves hence I will delve into these later.

Standard AWS backup, securtiy services and practices apply.
Security is based on IAM, security group, KMS encryption etc.
Please refer to the VPC page on this site to get an understanding of IAM. KMS, HSM key rotation etc will be covered sometime in the future.
Backups are snapshots that are stored on S3, AWS automatically run these backups and snapshots incrementally. The time intervals as per RDS data bases, need to be configured by the end user. (Configurable options are snapshot intervals and the retention period). Users can create their own snapshots when necessary.
One thing to note is that AWS have there own BI service known as quick site that can be utilized to visualize data on Redshift via dashboards.
Resizing the cluster will create a new cluster with the requested size, during the resizing period only the source cluster resources are charged for. Once the new resized cluster has been created DNS will repoint the to the new cluster endpoint (leader node url) and the old cluster will be terminated.